性能分析
原文: http://docs.cython.org/en/latest/src/tutorial/profiling_tutorial.html
这部分描述了 Cython 的性能分析能力。如果您熟悉纯 Python 代码的性能分析,只需要阅读第一节( Cython 性能分析基础)。如果您不熟悉 Python 性能分析,您还应该阅读教程( 分析教程 ),它将逐步引导您完成一个完整的示例。
Cython 性能分析基础
Cython 中的性能分析由编译器指令控制。它可以通过 Cython 装饰器设置为整个文件或基于每个功能。
启用完整源文件的分析
通过在文件顶部添加一个给 Cython 编译器的全局指令,可以开启整个源文件的性能分析:
# cython: profile=True
请注意,性能分析会给每个函数调用带来轻微的开销,因此会使程序变慢(或者很多,如果你经常调用一些微型函数)。
启用后,从 cProfile 模块调用时,您的 Cython 代码将像 Python 代码一样运行。这意味着您可以使用与仅 Python 代码相同的工具,将您的 Cython 代码与 Python 代码一起分析。
禁用分析功能
如果您的性能分析因为某些,您在性能分析报告中并不需要看到的,微型函数的调用开销而变得混乱时,无论是因为您计划内联它们还是因为您确定不能让它们更快,你都可以使用一个特殊的装饰器来禁用一个函数的性能分析(无论它是否全局启用):
cimport cython
@cython.profile(False)
def my_often_called_function():
pass
启用行跟踪
要获得更详细的跟踪信息(对于可以使用它的工具),您可以启用行跟踪:
# cython: linetrace=True
这也将启用性能分析支持,因此不需要上面的profile=True选项。例如,覆盖率分析需要线跟踪。
请注意,即使通过编译器指令启用了行跟踪,默认情况下也不会使用它。由于运行时减速可能很大,因此必须由 C 编译器通过设置 C 宏定义CYTHON_TRACE=1进行编译。要在跟踪中包含 nogil 函数,请设置CYTHON_TRACE_NOGIL=1(表示CYTHON_TRACE=1)。可以在setup.py脚本的扩展定义中定义 C 宏,也可以使用以下文件头注释设置源文件中的相应 distutils 选项(如果cythonize()用于编译):
# distutils: define_macros=CYTHON_TRACE_NOGIL=1
启用覆盖率分析
从 Cython 0.23 开始,线跟踪(见上文)也支持使用 coverage.py 工具报告覆盖率报告。要使覆盖率分析了解 Cython 模块,还需要在.coveragerc文件中启用 Cython 的 coverage 插件,如下所示:
[run]
plugins = Cython.Coverage
使用此插件,您的 Cython 源文件应该在 coverage 报告中正常显示。
要将覆盖率报告包含在 Cython 带注释的 HTML 文件中,您需要首先运行 coverage.py 工具以生成 XML 结果文件。将此文件传递到cython命令,如下所示:
$ cython --annotate-coverage coverage.xml package/mymodule.pyx
这将重新编译 Cython 模块并在其处理的每个 Cython 源文件旁边生成一个 HTML 输出文件,其中包含 coverage 报告中包含的行的颜色标记。
分析教程
这将是一个完整的教程,从头到尾,分析 Python 代码,将其转换为 Cython 代码并保持分析直到它足够快。
作为一个玩具示例,我们想要评估平方倒数的总和,直到某个整数 来评估
来评估 。我们想要使用的关系已经由欧拉在 1735 年证明并被称为巴塞尔问题。
。我们想要使用的关系已经由欧拉在 1735 年证明并被称为巴塞尔问题。
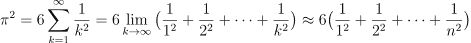
用于评估截断总和的简单 Python 代码如下所示:
# calc_pi.py
def recip_square(i):
return 1. / i ** 2
def approx_pi(n=10000000):
val = 0.
for k in range(1, n + 1):
val += recip_square(k)
return (6 * val) ** .5
在我这里,这需要大约 4 秒来运行这个使用n的默认值的函数。我们选择 n 越高,的近似值越好。经验丰富的 Python 程序员已经看到很多地方可以优化这段代码。但请记住优化的黄金法则:在做完性能分析之前绝不轻易优化代码。让我重复一遍:在做完性能分析之前绝不轻易优化代码。您对代码的哪一部分花费太多时间的想法是错误的。至少,我的总是错的。所以让我们编写一个简短的脚本来分析我们的代码:
# profile.py
import pstats, cProfile
import calc_pi
cProfile.runctx("calc_pi.approx_pi()", globals(), locals(), "Profile.prof")
s = pstats.Stats("Profile.prof")
s.strip_dirs().sort_stats("time").print_stats()
在我这里上运行它给出以下输出:
Sat Nov 7 17:40:54 2009 Profile.prof
10000004 function calls in 6.211 CPU seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
1 3.243 3.243 6.211 6.211 calc_pi.py:7(approx_pi)
10000000 2.526 0.000 2.526 0.000 calc_pi.py:4(recip_square)
1 0.442 0.442 0.442 0.442 {range}
1 0.000 0.000 6.211 6.211 <string>:1(<module>)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
它包含代码在 6.2 CPU 秒内运行的信息。请注意,代码慢了 2 秒,因为它在 cProfile 模块中运行。该表包含真正有价值的信息。您可能需要查看 Python 分析文档以获取详细信息。这里最重要的列是 totime(在此函数中花费的总时间而不是计算由此函数调用的函数)和 cumtime(在此函数中花费的总时间也计算所谓的函数通过这个功能)。查看 tottime 列,我们看到大约一半的时间花在 approx_pi 上,另一半花在 recip_square 上。还有半秒钟在范围内度过......当然我们应该使用 xrange 进行如此大的迭代。实际上,只需将范围更改为 xrange 就可以在 5.8 秒内运行代码。
我们可以在纯 Python 版本中进行优化,但由于我们对 Cython 感兴趣,让我们继续前进并将此模块带到 Cython。我们无论如何都会这样做,以使循环运行得更快。这是我们的第一个 Cython 版本:
# cython: profile=True
# calc_pi.pyx
def recip_square(int i):
return 1. / i ** 2
def approx_pi(int n=10000000):
cdef double val = 0.
cdef int k
for k in range(1, n + 1):
val += recip_square(k)
return (6 * val) ** .5
注意第一行:我们必须告诉 Cython 应该启用性能分析。这使得 Cython 代码稍慢,但如果没有这个,我们将无法从 cProfile 模块获得有意义的输出。其余代码大部分都没有改变,我只给一些变量注明了类型,这可能会加快一点速度。
我们还需要修改我们的性能分析脚本以直接导入 Cython 模块。这是添加 Pyximport模块导入的完整版本:
# profile.py
import pstats, cProfile
import pyximport
pyximport.install()
import calc_pi
cProfile.runctx("calc_pi.approx_pi()", globals(), locals(), "Profile.prof")
s = pstats.Stats("Profile.prof")
s.strip_dirs().sort_stats("time").print_stats()
我们只添加了两行,其余的完全相同。或者,我们也可以手动将代码编译成扩展库;我们根本不需要更改性能分析脚本。该脚本现在输出以下内容:
Sat Nov 7 18:02:33 2009 Profile.prof
10000004 function calls in 4.406 CPU seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
1 3.305 3.305 4.406 4.406 calc_pi.pyx:7(approx_pi)
10000000 1.101 0.000 1.101 0.000 calc_pi.pyx:4(recip_square)
1 0.000 0.000 4.406 4.406 {calc_pi.approx_pi}
1 0.000 0.000 4.406 4.406 <string>:1(<module>)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
运行时间减少了1.8秒。还不赖。将输出结果与前一个进行比较,我们看到 recip_square 函数变得更快,而 approx_pi 函数没有发生很大变化。让我们更专注于 recip_square 函数。首先请注意,不要从我们模块之外的代码调用此函数;所以将它变成 cdef 以减少调用开销是明智的。我们也应该摆脱幂运算符:它变成了 Cython 的 pow(i,2)函数调用,但我们可以改为编写 i * i,这可能更快。整个函数也很适合内联。让我们看看这些想法会带来什么变化:
# cython: profile=True
# calc_pi.pyx
cdef inline double recip_square(int i):
return 1. / (i * i)
def approx_pi(int n=10000000):
cdef double val = 0.
cdef int k
for k in range(1, n + 1):
val += recip_square(k)
return (6 * val) ** .5
现在运行性能分析脚本会产生:
Sat Nov 7 18:10:11 2009 Profile.prof
10000004 function calls in 2.622 CPU seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
1 1.782 1.782 2.622 2.622 calc_pi.pyx:7(approx_pi)
10000000 0.840 0.000 0.840 0.000 calc_pi.pyx:4(recip_square)
1 0.000 0.000 2.622 2.622 {calc_pi.approx_pi}
1 0.000 0.000 2.622 2.622 <string>:1(<module>)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
运行时间又快了1.8秒。这并不意外。为什么 recip_square 仍然在这个表中;应该是内联的,不是吗?这样做的原因是,即使消除了函数调用,Cython 仍会生成分析代码。让我们告诉它不再分析 recip_square 的性能;无论如何,我们都没法使这个函数更快了:
# cython: profile=True
# calc_pi.pyx
cimport cython
@cython.profile(False)
cdef inline double recip_square(int i):
return 1. / (i * i)
def approx_pi(int n=10000000):
cdef double val = 0.
cdef int k
for k in range(1, n + 1):
val += recip_square(k)
return (6 * val) ** .5
运行它显示了一个有趣的结果:
Sat Nov 7 18:15:02 2009 Profile.prof
4 function calls in 0.089 CPU seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.089 0.089 0.089 0.089 calc_pi.pyx:10(approx_pi)
1 0.000 0.000 0.089 0.089 {calc_pi.approx_pi}
1 0.000 0.000 0.089 0.089 <string>:1(<module>)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
首先要注意的是速度的巨大提升:这个版本只占我们第一个 Cython 版本的 1/50。另请注意,recip_square 已经从我们想要的表中消失了。但最奇特和重要的变化是,about_pi 也变得更快。这是所有分析的问题:在性能分析脚本运行中调用函数会给函数调用增加一定的开销。这个开销没有被加到被调用函数所花费的时间里,而是加到调用函数所花费的时间。在这个例子中,在最后一次运行中,approx_pi 不需要 2.622 秒;但它调用了 recip_square 10000000 次,每次都需要稍微设置一下它的性能分析。这相当于大约 2.6 秒的时间损失。禁用经常调用的函数的性能分析会揭示 approx_pi 的实际时间;如果需要,我们现在还可以继续优化它。
这个分析教程到此结束。此代码仍有一些改进空间。我们可以尝试用 C stdlib 中的 sqrt 调用替换 approx_pi 中的幂运算符;但这并不一定比调用 pow(x,0.5)更快。
即便如此,我们在这里取得的成果非常令人满意:我们提出了一个比原始 Python 版本快得多的解决方案,同时保留了功能和可读性。
